介绍¶
动机¶
过去十年中,深度神经网络(DNN)已成为一类重要的机器学习(ML)模型,能够在从自然语言处理 [SUTSKEVER2014] 到计算机视觉 [REDMON2016] 再到计算神经科学 [LEE2017] 的许多领域达到最先进的性能。这些模型的优势在于其分层结构,由一系列参数化(例如,卷积)和非参数化(例如,修正线性)的*层*组成。尽管这种模式在计算上非常昂贵,但它也产生了大量高度可并行化的工作,特别适合多核和众核处理器。
因此,图形处理单元(GPU)已成为在该领域探索和/或部署新颖研究思路的廉价且易于获取的资源。通用 GPU(GPGPU)计算框架的发布,例如 CUDA 和 OpenCL,加速了这一趋势,使高性能程序的开发变得更容易。然而,GPU 在局部性和并行性优化方面仍然极具挑战性,特别是对于无法有效地使用现有优化原语组合实现的计算。更糟糕的是,GPU 架构也在迅速演进和专业化,例如 NVIDIA(最近还有 AMD)微架构中增加了 Tensor Core。
DNN 提供的计算机会与 GPU 编程的实际困难之间的这种矛盾,引发了学术界和工业界对领域特定语言(DSLs)和编译器的浓厚兴趣。遗憾的是,这些系统——无论是基于多面体机制(例如,Tiramisu [BAGHDADI2021]、Tensor Comprehensions [VASILACHE2018])还是调度语言(例如,Halide [JRK2013]、TVM [CHEN2018])——与 cuBLAS、cuDNN 或 TensorRT 等库中提供的最佳手写计算内核相比,仍然缺乏灵活性,且(对于相同的算法)速度明显较慢。
本项目的主要前提如下:基于分块算法 [LAM1991] 的编程范式可以促进构建用于神经网络的高性能计算内核。我们特别重新审视了用于 GPU 的传统“单程序多数据”(SPMD [AUGUIN1983])执行模型,并提出了一种变体,其中程序而非线程被分块。例如,在矩阵乘法的情况下,CUDA 和 Triton 的区别如下:
CUDA 编程模型 (标量程序,分块线程) |
Triton 编程模型 (分块程序,标量线程) |
|---|---|
#pragma parallel
for(int m = 0; m < M; m++)
#pragma parallel
for(int n = 0; n < N; n++){
float acc = 0;
for(int k = 0; k < K; k++)
acc += A[m, k] * B[k, n];
C[m, n] = acc;
}
|
#pragma parallel
for(int m = 0; m < M; m += MB)
#pragma parallel
for(int n = 0; n < N; n += NB){
float acc[MB, NB] = 0;
for(int k = 0; k < K; k += KB)
acc += A[m:m+MB, k:k+KB]
@ B[k:k+KB, n:n+NB];
C[m:m+MB, n:n+NB] = acc;
}
|
|
|
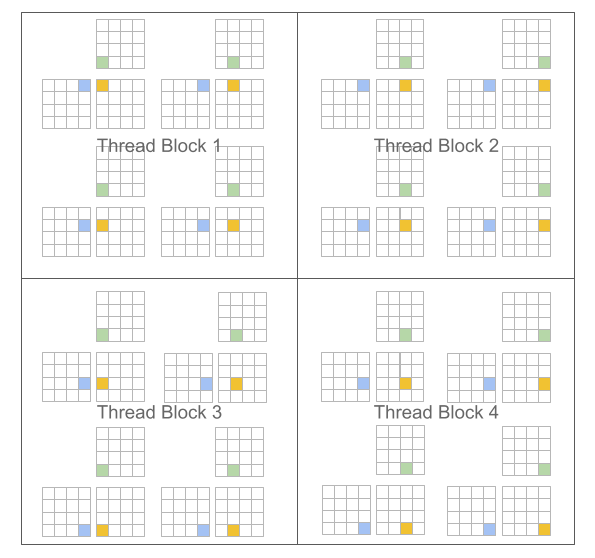
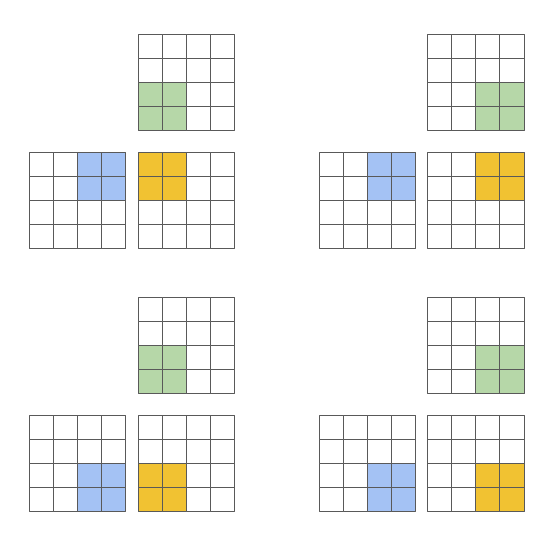
这种方法的一个主要优点是它产生了块状结构的迭代空间,与现有 DSL 相比,为程序员在实现稀疏操作时提供了更大的灵活性,同时允许编译器积极优化程序的局部性和并行性。
挑战¶
我们提出的范式带来的主要挑战是工作调度,即如何分割每个程序实例完成的工作以便在现代 GPU 上高效执行。为了解决这个问题,Triton 编译器大量使用了*块级数据流分析*,这是一种根据目标程序的控制流和数据流结构静态调度迭代块的技术。由此产生的系统实际上效果出人意料地好:我们的编译器能够自动应用广泛的有趣优化(例如,自动合并、线程交织、预取、自动向量化、Tensor Core 感知指令选择、共享内存分配/同步、异步复制调度)。当然,做到这一切并不简单;本指南的目的之一就是让你了解其工作原理。
参考¶
Sutskever 等人,“Sequence to Sequence Learning with Neural Networks”,NIPS 2014
Redmon 等人,“You Only Look Once: Unified, Real-Time Object Detection”,CVPR 2016
Lee 等人,“Superhuman Accuracy on the SNEMI3D Connectomics Challenge”,ArXiV 2017
Baghdadi 等人,“Tiramisu: A Polyhedral Compiler for Expressing Fast and Portable Code”,CGO 2021
Vasilache 等人,“Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions”,ArXiV 2018
Ragan-Kelley 等人,“Halide: A Language and Compiler for Optimizing Parallelism, Locality, and Recomputation in Image Processing Pipelines”,PLDI 2013
Chen 等人,“TVM: An Automated End-to-End Optimizing Compiler for Deep Learning”,OSDI 2018
Lam 等人,“The Cache Performance and Optimizations of Blocked Algorithms”,ASPLOS 1991
Auguin 等人,“Opsila: an advanced SIMD for numerical analysis and signal processing”,EUROMICRO 1983